

Estamos navegando tranquilamente por las aguas de Internet cuando, de pronto, un molesto Captcha nos solicita que demostremos ser humanos. Nosotros deseando bajarnos el fichero y, en lugar de eso, vemos dos imágenes para transcribir. Qué bien, ¿no?
¿Por qué? ¿Por qué no navegar directamente con un certificado único que me identifique como humano y que me permita navegar tranquilo sin necesidad de demostrar constantemente que no soy un malvado ciborg del futuro o que no tengo nada que ver con Sarah Connor? Pues porque con los captchas estoy ayudando a digitalizar las bibliotecas del mundo.
Nuestro pasado está escondido en las bibliotecas del mundo
¿Sabes cuántos documentos antiguos hay en el mundo a los que no tenemos acceso? Cuando digo antiguos me refiero a esos documentos que solo se encuentran en un formato físico o digital en imagen, pero cuyo contenido no está indizado en ningún sitio, sencillamente porque resulta costoso transcribirlo y subirlo a Internet. Un documento que no podemos buscar.
Te reto a que adivines la cifra, aunque sea orientativa. ¿Cuántos documentos así hay en el planeta? ¿Cientos, miles, millones, cientos de miles de millones? Es muy probable que cualquier estimación se quede corta… Y hablamos de nuestra historia, de algo relevante para nuestro futuro y que deberíamos conocer de buena mano.

La Biblioteca Vasconcelos, una de los espacios más racionales y ordenados, sigue siendo para muchos un laberinto de páginas. Imagen: Urban 360
En la imagen superior vemos la Biblioteca Vasconcelos (Ciudad de México, 2006), una de las más ordenadas y accesibles del planeta. Incluso aunque su catálogo pertenece a uno actualizado y moderno, sigue siendo un laberinto de información casi inaccesible al lector de a pie. ¡Y hablamos de una biblioteca moderna con un catálogo que puede ser leído por sus usuarios!
Nada que ver con los catálogos ocultos de las grandes bibliotecas, de las que escogidas al azar buscando por «biblioteca»: la Biblioteca Nacional de España (20.000.000), La Biblioteca Británica (150.000.000), La Biblioteca Real de Dinamarca (32.000.000), el edificio Thomas Jefferson (158.000.000), la Biblioteca Nacional Rusa (35.000.000).
Esos números que aparecen junto al nombre son documentos que guardan las bibliotecas, mezcla de libros, folletos, hojas sueltas, revistas, diarios, impresos antiguos, incunables, manuscritos, dibujos, grabados, fotografías, exlíbris, ephemeras, carteles, mapas y planos, postales, partituras, registros sonoros y audiovisuales, microformas,…
Documentos históricos inaccesibles al público. Parte de lo que somos y nuestra historia, escondido. Tomar decisiones sobre nuestro futuro siempre es complejo, pero resulta más fácil saber a dónde se va si se conoce de dónde se ha estado (y cómo se ha pasado allí).
Cuatrocientos millones de textos inaccesibles a la gente en tan solo cinco bibliotecas de las miles que existen, más las cientos de miles que incluyen pequeños museos, colecciones en templos de culto, colecciones privadas, e incluso silos sin catalogar. El número total resulta inabarcable. Pero hoy, más que nunca, necesitamos conocer nuestro pasado.
Cómo se digitaliza un documento
Hay varios métodos de hacer digital y público un documento. El primero es creando un índice de búsqueda sencillo, como el que tiene una biblioteca normal. Si busco por un título, autor, ISBN, editorial, etc, en una base de datos, esta me devuelve la planta, columna y altura a la que está el libro dentro de la misma.
Para textos modernos que se encuentran en tiendas, librerías y otras bibliotecas no es necesario que todas sus páginas estén accesibles en formato web, ya que siempre podremos acceder a una lectura gratuita.
El segundo método es volcar parte de su contenido a una Biblioteca online junto con un escaneado del mismo. En esto, la Biblioteca Digital Hispánica es puntera, y cuenta con más de 138.000 títulos que van desde páginas sueltas a dibujos arquitectónicos. Por ejemplo, esta digitalización en imágenes sobre el Arte de los relojes de ruedas, un documento con 649 páginas.

Arte de reloxes de ruedas para torre, sala y faltriquera, Don Antonio Cruzado, 1798. Tomo primero, página 1 y Tomo primero, página 73. Fuente: Biblioteca Digital Hispánica
Un paso más allá es el reconocimiento del texto en una imagen gracias a programas de reconocimiento de formas (como el programa de reconocimiento facial o de matrícula de la policía). Si el lector hace clic en el primer enlace bajo la imagen anterior, podrá arrastrar con el ratón sobre el texto, y copiarlo.
No será así en el segundo enlace, ya que el programa de reconocimiento no detecta más que dibujos o grabados, y no tiene acceso a la información escrita, pese a que esta existe en la lámina escaneada. Es aquí donde entran en juego los captchas, ya que estos usan al usuario (por lo general un humano) para decirle a la imagen qué texto hay en ella.
Cómo funcionan los Captchas y el reCaptcha
La idea del Captcha empezó simplemente para diferenciar humanos de robots, para separar el grano de la paja y que los sitios web estuviesen libres de spam. Sin embargo, su inventor, Luis von Ahn, tuvo la idea de que los Captchas (ahora reCaptchas) ayudasen a digitalizar nuestras saturadas bibliotecas repletas de volúmenes sin acceso público.
Para ello, introdujo dos fragmentos en el Captcha. El primero es conocido por el ordenador, mientras que el segundo no lo es. Pongamos el ejemplo de la segunda lámina, la no digitalizada en formato texto. Dado que el ordenador ya reconoce la palabra:
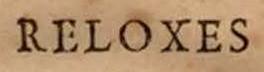
como «R-E-L-O-X-E-S» en la primera lámina, creará el siguiente reCaptcha:
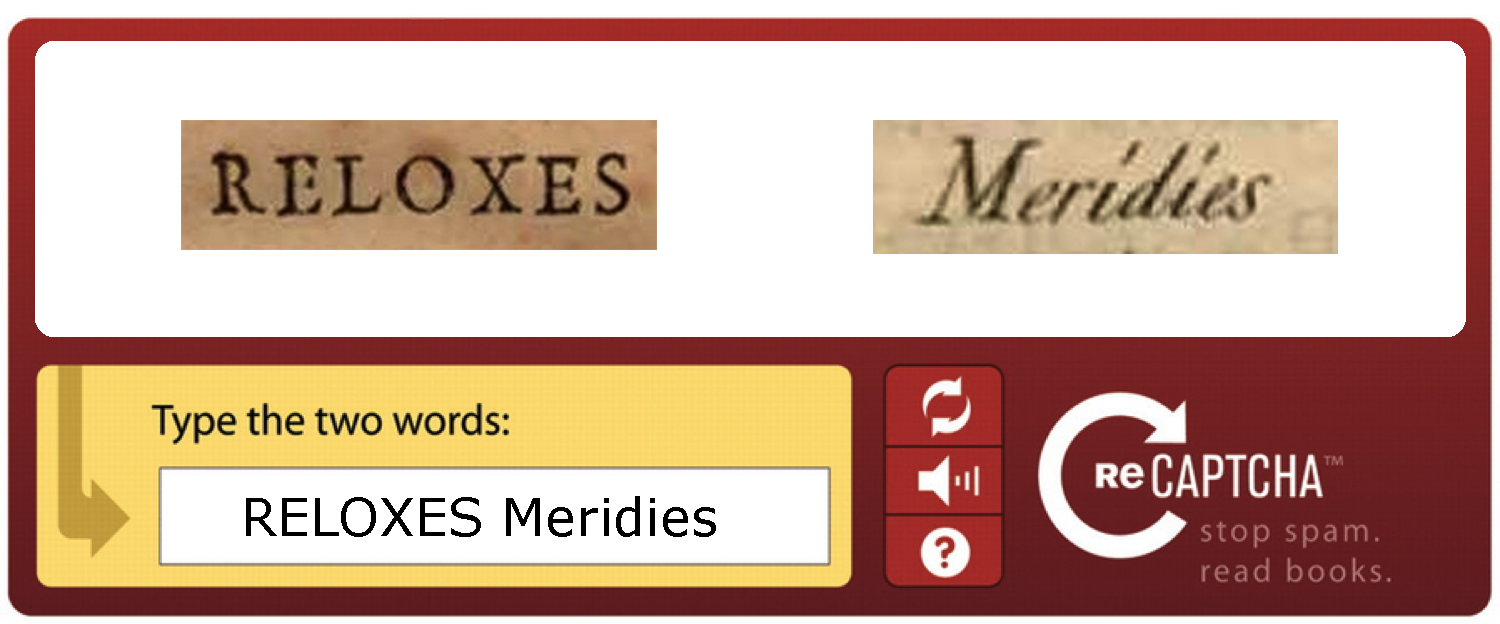
Captcha inventado para ilustrar su funcionamiento. Fuente: Marcos Martínez
El usuario, al introducir bien la primera palabra, le está diciendo al sistema que es humano (y que además tiene una vista excelente), y al introducir la segunda está haciendo que el ordenador lea Meridies donde él ve:
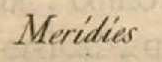
Esto se aplica a textos poco legibles, girados, con manchas… textos que el ordenador detecta como tales pero que ve incapaz el asignar una letra u otra a un borrón informe. Se empezó a usar para el New York Times y ahora Google (propietario de la compañía reCaptcha) escanea miles de libros al año para hacerlos accesibles.
¿Por qué digitalizar documentos?
La respuesta rápida es porque la gente tiene todo el derecho del mundo a poder analizar y estudiar su patrimonio cultural. El problema, hasta ahora, es que ese patrimonio cultural es de acceso público pero restringido por el cuidado con que hay que tratar algunos documentos, o bien porque su dueño considera peligroso su trato.
El proceso actual para consultar documentos públicos en bibliotecas estatales y colecciones privadas asociadas no se parece nada al guión de La búsqueda, e incurre en muchos menos robos, explosiones y frases mal guionizadas. En su lugar, disponemos de un sistema lento, burocratizado y poco accesible.

Documento antiguo. Fuente: Michal Jarmoluk
Se ha de solicitar acceso formal al documento, que se llevará a cabo (si es que te lo dan) en condiciones higiénicas de laboratorio, en un plazo y lugar concreto, y bajo la supervisión de personal de seguridad y conservadores. ¿Y si se acaba el tiempo y no he localizado lo que busco? Vuelta a solicitar permiso, vuelta a empezar.
Como poco, este método es contraproducente para una lectura seria de nuestro pasado, ya que estudiantes y lectores ven muy complicado el poder acceder no ya a uno o dos documentos, sino a varios centenares con objeto de estudiarlos y relacionarlos entre sí. Una labor titánica que genera graves errores al hacer estudios de otros estudios (en lugar de los textos originales).
Cuando todo el mundo tenga acceso a todos los documentos de nuestro pasado, entonces quizá sepamos un poco mejor a dónde queremos dirigirnos en nuestro futuro.
Imagen de portada | Alzado y planta de un puente francés (1665)